 手機版
手機版 化工儀器網手機版
化工儀器網手機版
 化工儀器網小程序
化工儀器網小程序
 官方微信
官方微信 公眾號:chem17
公眾號:chem17
 掃碼關注視頻號
掃碼關注視頻號
")











生物催化劑在能源,、材料和醫(yī)藥領域具有重要應用,如何高效,、精準地設計并篩選出具有特定功能的生物催化劑一直是研究熱點。然而,,當前酶的定向進化方法存在很多局限性,設計與篩選過程往往耗時費力,,且受限于生物體內復雜的遺傳與環(huán)境因素。因此,,開發(fā)一種高效,、靈活且可控的生物催化劑設計與篩選平臺顯得尤為重要,。
今天,,小編將和您分享一篇今年發(fā)表于《Nature Communications》上的文獻“Accelerated enzyme engineering by machine-learning guided cell-free expression”,該文獻介紹了一種全新的高通量方法,,用于探索化學空間多個區(qū)域的適應度景觀,,以實現生物催化劑的前瞻性設計,。(注:適應度景觀是一種理論模型,它將每個可能的蛋白質序列映射到一個適應度值上,。適應度可以理解為該蛋白質在特定環(huán)境下的功能表現或生存優(yōu)勢,。)

一,、研究背景
酶工程旨在通過改造蛋白質序列來增強天然功能或賦予新功能,,傳統定向進化方法通過反復突變與篩選優(yōu)化酶性能,但存在顯著瓶頸:
1.序列空間探索受限,,低通量篩選難以覆蓋序列空間,,可能遺漏關鍵協同突變,;
2.多目標優(yōu)化困難,單一酶需適配多種底物或反應(如合成不同藥物分子),,但現有方法難以并行優(yōu)化多個功能目標,;
3.數據生成效率低,構建高質量序列-功能數據集需合成并測試海量突變體,,傳統方法依賴于體內表達系統,,但這一過程受到細胞生長周期,、穩(wěn)態(tài)條件及生產適應性等多重因素的制約,導致篩選效率低下且成本高昂,。
盡管機器學習為酶設計提供了新思路,,但如何高效構建大規(guī)模序列-功能數據集仍是核心挑戰(zhàn)。為了應對這一挑戰(zhàn),,研究團隊開發(fā)了一個集成無細胞DNA組裝、無細胞蛋白表達和蛋白功能分析的平臺,,能夠快速生成新的適用性蛋白序列并快速驗證這些新蛋白序列的實際功能,,并優(yōu)化多種不同化學反應的酶,。

圖1:機器學習指導的無細胞酶工程平臺
二,、無細胞表達技術的突破性作用
無細胞表達系統作為一種新興的生物技術平臺,,為生物催化劑的設計與篩選提供了新的解決方案。該系統能夠在體外環(huán)境中快速合成并測試蛋白質,,不受細胞生長周期及穩(wěn)態(tài)條件的限制,,因此具有更高的靈活性和可控性。在本篇文獻中,,研究團隊利用無細胞表達系統結合機器學習算法,構建了一個高通量的生物催化劑設計與篩選平臺,。該平臺能夠在短時間內合成并測試大量具有不同序列的蛋白質,,并通過機器學習算法預測并篩選出具有催化性能的候選者。這一方法不僅顯著提高了篩選效率,,還降低了成本,,為生物催化劑的前瞻性設計提供了有力支持。
具體來說,,本研究通過以下創(chuàng)新解決了現有酶工程的技術難點:
1. 高通量無細胞系統
利用無細胞DNA組裝與表達,用于構建定點飽和,、序列明確的蛋白質庫,。工作流程包括五個步驟:通過PCR引入突變、DpnI消化親本質粒,、 Gibson組裝形成突變質粒,、第二次PCR擴增線性DNA表達模板(LETs)、通過CFE(無細胞蛋白表達系統)表達突變蛋白,。該方法可在一天內構建數百到數千個序列明確的蛋白質突變體,,并可通過快速迭代積累突變。此外,,使用單體超穩(wěn)定綠色熒光蛋白(muGFP)驗證了該工作流程,,針對四個已知對穩(wěn)定性和熒光重要的殘基進行突變。實驗結果表明,,該方法對引物設計偏差具有高容忍度,,并且所有預期突變均成功引入,。
2. 機器學習模型加速設計
基于單突變數據訓練增強嶺回歸模型,,并使用歸一化折損累積增益(NDCG)評估模型預測性能,結合進化與物理化學特征編碼,,成功預測多突變組合的活性,。模型從80個單突變數據中推斷高階突變,,實驗驗證顯示預測變體的活性提升達1.6-42倍(如抗抑郁藥莫氯貝胺的轉化率從12%提升至96%)。

圖2:工作流程示意圖
3. 并行優(yōu)化多反應目標
研究團隊開發(fā)了一個能夠加速生物催化反應并顯著減少篩選的工作量的并行優(yōu)化流程,,他們選擇了具有底物普適性的酶McbA作為研究對象,通過并行處理多個反應,,同時測試不同的突變體,,從而快速識別出具有更高催化活性的突變體。為了進一步提高篩選效率,,研究者們采用了機器學習技術來預測突變體的催化活性,。通過訓練模型,,根據突變體的序列信息預測其催化活性,。并且能夠在實驗前對突變體進行初步篩選,,從而減少了實驗驗證的工作量。相比于ISM(iterative saturation mutagenesis)單獨使用,,此框架顯著加快了工程進度,,可在一周內同時完成六種酶的改造任務,突變體的產量提高了1.6到34倍,。另外,,該方法成本低廉(每10微升反應僅需幾分錢)且具有高可擴展性。
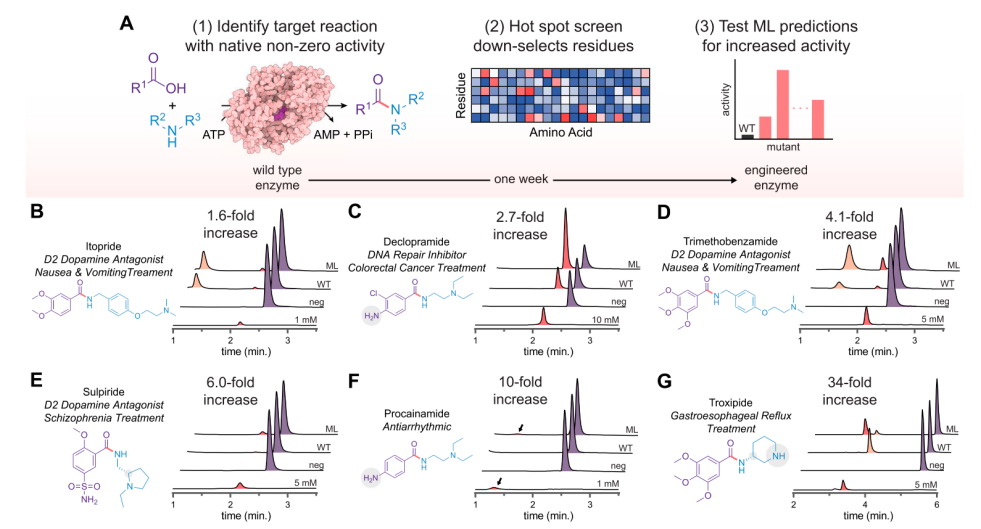
圖3:用于McbA機器學習引導的蛋白質工程策略
總結與展望
本研究將無細胞系統的高通量優(yōu)勢與機器學習的預測能力結合,用于生物催化劑的前瞻性設計,。實現酶工程從單目標到多任務的跨越式發(fā)展,,為可持續(xù)生物制造注入新動力。不僅突破了傳統酶工程的效率瓶頸,,使其同時具備速度與通量,、精準預測能力等,還顯著提高了生物催化劑的設計與篩選效率,為綠色化學與定制化生物催化劑開發(fā)提供了全新范式,。隨著技術的不斷進步和創(chuàng)新,無細胞表達系統有望為生物技術領域帶來更多機遇和挑戰(zhàn),。
參考文獻:Landwehr, G.M. et al. Accelerated enzyme engineering by machine-learning guided cell-free expression. *Nat. Commun.* **16**, 865 (2025).
相關產品




免責聲明
- 凡本網注明“來源:化工儀器網”的所有作品,均為浙江興旺寶明通網絡有限公司-化工儀器網合法擁有版權或有權使用的作品,,未經本網授權不得轉載,、摘編或利用其它方式使用上述作品。已經本網授權使用作品的,,應在授權范圍內使用,,并注明“來源:化工儀器網”。違反上述聲明者,,本網將追究其相關法律責任,。
- 本網轉載并注明自其他來源(非化工儀器網)的作品,目的在于傳遞更多信息,,并不代表本網贊同其觀點和對其真實性負責,,不承擔此類作品侵權行為的直接責任及連帶責任,。其他媒體,、網站或個人從本網轉載時,,必須保留本網注明的作品第一來源,,并自負版權等法律責任。
- 如涉及作品內容,、版權等問題,請在作品發(fā)表之日起一周內與本網聯系,,否則視為放棄相關權利,。


 采購中心
采購中心