化工儀器網(wǎng)
化工儀器網(wǎng)
公司動態(tài)
提供實驗數(shù)據(jù)分析服務(wù),,聚類分析,基因注釋數(shù)據(jù)分析
閱讀:1756 發(fā)布時間:2017-2-17世聯(lián)博研(北京)科技有限公司(BIO EXELLENCE INTERNATIONAL Tech Co.,Ltd)專注力學(xué)生物學(xué)(細(xì)胞組織生物分子力學(xué))與3D生物打印,應(yīng)廣大科研者要求,,世聯(lián)博研在代理銷售科研儀器設(shè)備及配套耗材的同時提供細(xì)胞力學(xué)實驗技術(shù)服務(wù)和3D生物打印實驗技術(shù)服務(wù)以及數(shù)據(jù)分析服務(wù),。
世聯(lián)博研數(shù)據(jù)分析團隊由來自微軟、華為,、中科院,、農(nóng)科院的力學(xué)、生物信息學(xué),、計算機專業(yè)人員組成,,其中博士以上學(xué)歷者占50%以上,在圖像處理,、蛋白質(zhì)組學(xué),、轉(zhuǎn)錄組學(xué)、基因組學(xué),、數(shù)值模擬及數(shù)據(jù)可視化處理方面擁有豐富的經(jīng)驗,。公司建立了高性能計算平臺,具有強大的數(shù)據(jù)儲存和處理能力,,使用Linux,、R、Perl,、Python,、C++等工具進行數(shù)據(jù)處理,可為客戶定制數(shù)據(jù)分析服務(wù)并提供咨詢,,將符合期刊發(fā)表要求的結(jié)果發(fā)送給客戶,。
數(shù)據(jù)分析服務(wù) 世聯(lián)博研數(shù)據(jù)分析團隊由來自微軟、華為,、中科院,、農(nóng)科院的力學(xué)、生物信息學(xué),、計算機專業(yè)人員組成,,其中博士以上學(xué)歷者占50%以上,在圖像處理,、蛋白質(zhì)組學(xué),、轉(zhuǎn)錄組學(xué)、基因組學(xué),、數(shù)值模擬及數(shù)據(jù)可視化處理方面擁有豐富的經(jīng)驗,。公司建立了高性能計算平臺,具有強大的數(shù)據(jù)儲存和處理能力,,使用Linux,、R、Perl,、Python,、C++等工具進行數(shù)據(jù)處理,可為客戶定制數(shù)據(jù)分析服務(wù)并提供咨詢,,將符合期刊發(fā)表要求的結(jié)果發(fā)送給客戶,。
聚類分析(cluster analysis)是一類將數(shù)據(jù)所研究對象進行分類的統(tǒng)計方法。這一類方法的共同點是事先不知道類別的個數(shù)與結(jié)構(gòu);據(jù)以進行分析的數(shù)據(jù)是對象之間的相似性或相異性的數(shù)據(jù),。將這些相似(相異)性數(shù)據(jù)看成是對象之間的“距離”遠(yuǎn)近的一種度量,,將距離近的對象歸入一類,不同類之間的對象距離較遠(yuǎn),。這就是聚類分析方法的共同思路,。具體在生物學(xué)研究中,基因表達譜分析經(jīng)常采用聚類分析的方法,,其目的就是將基因或者樣本進行分組,。從數(shù)學(xué)的角度,聚類得到基因分組,,組內(nèi)各成員在數(shù)學(xué)特征上彼此相似,,但與其它組中的成員不同。其基本假設(shè)是組內(nèi)基因的表達譜相似,,它們可能具有功能相關(guān)性,。大量功能相關(guān)的基因,特別是被共同的轉(zhuǎn)錄因子調(diào)控的基因表達譜非常相似,,它們的產(chǎn)物可能構(gòu)成蛋白質(zhì)復(fù)合體,,或者處于同一個調(diào)控通路中,因此還可以據(jù)此推測未知基因的功能并評估實驗的合理性(圖1),。 聚類分析根據(jù)分類對象不同分為Q型聚類和R型聚類,。Q型聚類是指對樣本進行聚類,R型聚類是指對變量進行聚類分析,。根據(jù)聚類方法可以分為系統(tǒng)聚類和動態(tài)聚類,。系統(tǒng)聚類法一次形成類后就不再改變,而動態(tài)聚類開始先粗略地分一下類,,然后按照某種*原則修改不合理的分類,,直至類分得比較合理,如K-均值聚類等,,適用于大樣本的Q型聚類分析,。
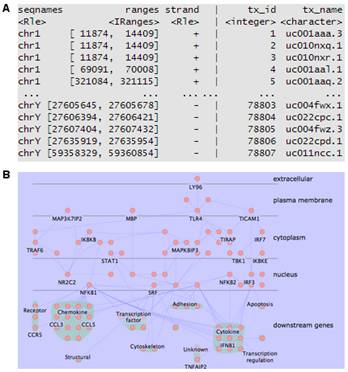
在基因芯片或者轉(zhuǎn)錄組學(xué)研究中,,得到基因列表之后通常要對高達數(shù)千種基因或蛋白進行注釋,以得到其各種名字的對應(yīng)關(guān)系,、染色體定位及亞細(xì)胞定位來方便后續(xù)的研究,。由于注釋數(shù)據(jù)庫的數(shù)量在不斷增加,且不斷進行著各種修改,,所以在高通量組學(xué)研究中很難對這些信息進行整合,。針對這些問題,我們開發(fā)了專門的組學(xué)數(shù)據(jù)注釋流程,,可方便地進行基因ID轉(zhuǎn)換(圖2 A),并確定相應(yīng)蛋白的亞細(xì)胞定位,,以推測其功能(圖2 B),。
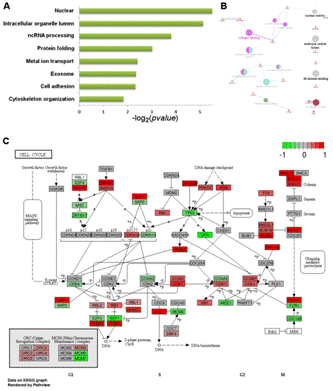
隨著轉(zhuǎn)錄組學(xué)及蛋白質(zhì)組學(xué)的發(fā)展,,現(xiàn)在已經(jīng)可以一次性得到大量的基因表達數(shù)據(jù)。對這些數(shù)據(jù)進行分析時通常采用功能富集分析的方法(圖3),,而非僅僅分析單個基因,,以避免單基因分析可能產(chǎn)生的偏差,從而得到更準(zhǔn)確的結(jié)論,。進行功能富集分析需要可靠的數(shù)據(jù)庫和強健的算法(如累積超幾何分布,、Fisher檢驗等),把涉及相同通路和功能的基因/蛋白質(zhì)進行歸類,,有助于生物學(xué)問題的解決,。
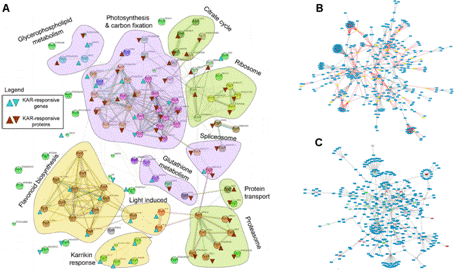
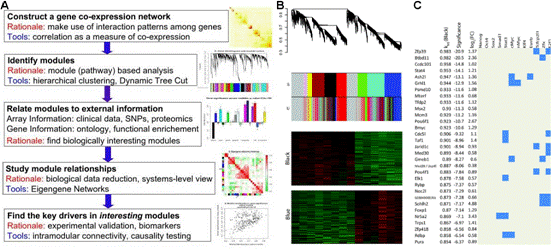
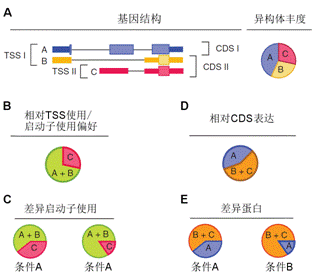
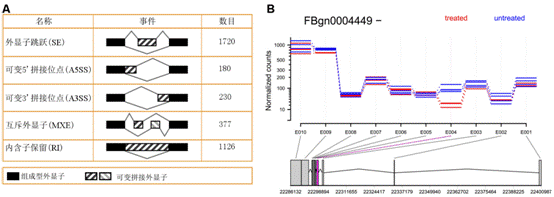
基因編碼的蛋白質(zhì)不但會單獨行使功能,,還會與其它蛋白質(zhì)之間存在著相互作用,,這種相互作用使其功能更加多樣化,且可以進行各種調(diào)控,。所以,,隨著后基因組時代的到來,蛋白質(zhì)相互作用研究受到了越來越多的重視?,F(xiàn)已有很多數(shù)據(jù)庫和工具進行蛋白互作(包括物理互作和功能互作)數(shù)據(jù)的儲存和處理,,其數(shù)據(jù)主要來自于基因組結(jié)構(gòu),、高通量實驗、共表達實驗和文獻挖掘,。將蛋白質(zhì)相互作用網(wǎng)絡(luò)進行圖形化展示,,為其功能關(guān)系提供了高層次神力,有助于生物學(xué)過程的模塊化分析(圖4),。 5.權(quán)重基因共表達分析 常規(guī)的差異表達分析方法大大促進了生物學(xué)的發(fā)展,取得了很多重大發(fā)現(xiàn),,但是,,這些方法都忽略了基因表達模式之間的相關(guān)性。結(jié)果,,這些數(shù)據(jù)產(chǎn)生的信息數(shù)量很多,,卻很難從中發(fā)現(xiàn)有價值的線索,無法確定差異表達基因的優(yōu)先級,,更難以去研究潛在的生物學(xué)通路,。相反,相關(guān)性網(wǎng)絡(luò)(又稱為共表達網(wǎng)絡(luò))可以發(fā)現(xiàn)彼此相關(guān)的基因(圖5 A),,并將其分為相應(yīng)的cluster(即共表達模塊)(圖5 B),,然后計算得到模塊中權(quán)重zui高的基因,將其做為關(guān)鍵調(diào)節(jié)因子(圖5 C),,從而簡化了數(shù)據(jù)的分析過程,,能夠的從數(shù)據(jù)中提取出關(guān)鍵信息,現(xiàn)已有大量的研究采用了這種方法,。 6.高能量測序數(shù)據(jù)分析(差異基因表達、差異異構(gòu)體表達,、可變拼接) 細(xì)胞內(nèi)基因表達水平時刻處于變化之中,,具有顯著的時間、組織,、條件特異性,,同時許多基因還具有不同的異構(gòu)體(圖6.1),測定不同刺激條件下的基因及其異構(gòu)體的表達變化對于闡明相關(guān)的生物學(xué)過程極為重要,。RNAseq技術(shù)可以一次性鑒定出大量的差異表達基因/異構(gòu)體,,從而在系統(tǒng)水平了解生命活動的機制,,也可以篩選出重要基因進行更深的功能研究。 可變拼接(AS)是真核生物基因表達調(diào)控的重要機制之一,。RNAseq已成為定量分析細(xì)胞內(nèi)的可變拼接的強有力工具,隨著高通量測序儀的不斷涌現(xiàn),,RNSseq的數(shù)據(jù)量也在以指數(shù)形式增加。在此背景下,,我們提供了可變拼接分析服務(wù),,對特定基因以及大規(guī)模轉(zhuǎn)錄組數(shù)據(jù)的可變拼接(圖6.2 A)、差異外顯子使用(圖6.2 B)等進行定量分析,。
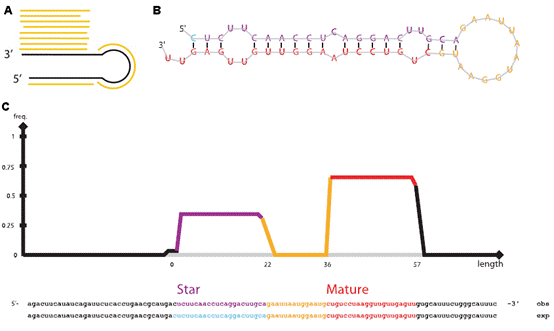
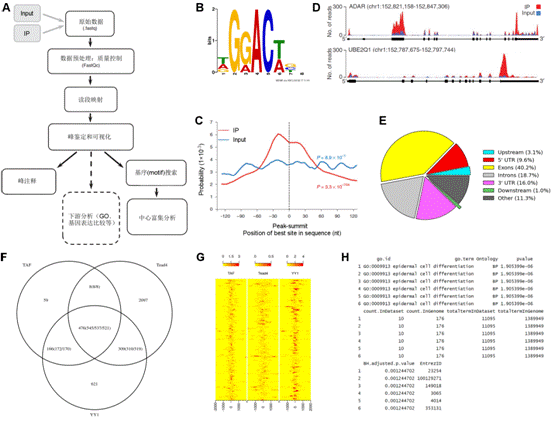
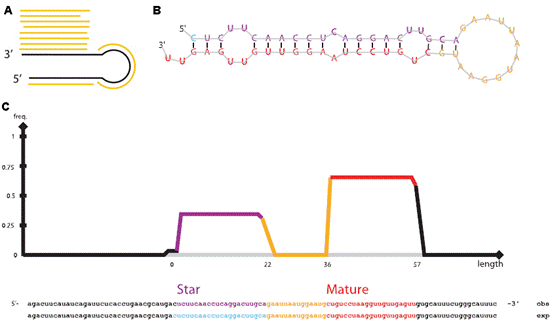
7.microRNA數(shù)據(jù)分析 MicroRNA (miRNA) 是一類由內(nèi)源發(fā)卡結(jié)構(gòu)轉(zhuǎn)錄本產(chǎn)生的長度約為22個核苷酸的非編碼單鏈RNA 分子,通過與靶mRNA分子互補配對進行轉(zhuǎn)錄后調(diào)控,。提取細(xì)胞內(nèi)全部RNA后進行小RNA建庫,,然后進行高通量測序,通過特定的算法(圖7 A),,由測序數(shù)據(jù)可得到已知的和新的miRNA分子前體(圖7 B),,并對此前體產(chǎn)生的miRNA進行定量(圖7 C)。 8.染色質(zhì)免疫共沉淀(ChIP)分析 染色質(zhì)免疫沉淀結(jié)合高通量測序技術(shù)(ChIP-seq)是鑒定基因組范圍內(nèi)DNA/RNA結(jié)合蛋白靶位點的標(biāo)準(zhǔn)方法,,現(xiàn)已開始在力學(xué)生物學(xué)中得到應(yīng)用,用于研究力學(xué)刺激下的蛋白質(zhì)-DNA相互作用,。Chip-seq先富集目標(biāo)蛋白結(jié)合的DNA/RNA片段,,然后純化和建庫并進行高通量測序,。得到的原始數(shù)據(jù)經(jīng)過特定的數(shù)據(jù)處理流程(圖8 A),可得到全基因組范圍內(nèi)與目標(biāo)蛋白互作的DNA序列信息(圖8 B,、C),、基因不同位置的分布(圖8 D、E),、比較不同的生物學(xué)重復(fù)之間的重復(fù)性(圖8 F),、結(jié)合位點熱圖(圖8 G),并對峰相關(guān)的基因進行GO功能富集分析(圖8 H)等。 9,、主成分分析 10,、HITS-CLIP分析 11,、宏基因組分析 12、外顯子測序分析 13,、單細(xì)胞測序分析 |